-
[코드리뷰] NeRFusion Code BreakdownNeRF 2023. 7. 31. 14:41
작성중
* 해당 포스팅은 NeRFusion official code (Pytorch)를 기반으로 합니다.
▶ NeRFusion 논문 리뷰: 2023.07.27 - [Papers] - [논문리뷰] NeRFusion: Fusing Radiance Fields for Large-Scale Scene Reconstruction
▶ NeRF 코드 리뷰: 2023.07.03 - [NeRF] - [코드리뷰] NeRF Code Breakdown
[코드리뷰] NeRF Code Breakdown
작성중 Prepare Dataset if not os.path.exists('tiny_nerf_data.npz'): !wget http://cseweb.ucsd.edu/~viscomp/projects/LF/papers/ECCV20/nerf/tiny_nerf_data.np data = np.load('tiny_nerf_data.npz') images = data['images'] poses = data['poses'] focal = data['f
libby-yu.tistory.com
본 포스팅에서는 논문에서 중요하게 다뤄진 부분을 중점적으로 리뷰하였습니다. Official 코드에서 중요한 부분(GRU, Local Voxel, Global Voxel)에 대한 구현 코드를 train시에 어떻게 사용하는지 공개하지 않았기 때문에, 아래 Figure 2.에 관한 작동 과정 코드는 없습니다.
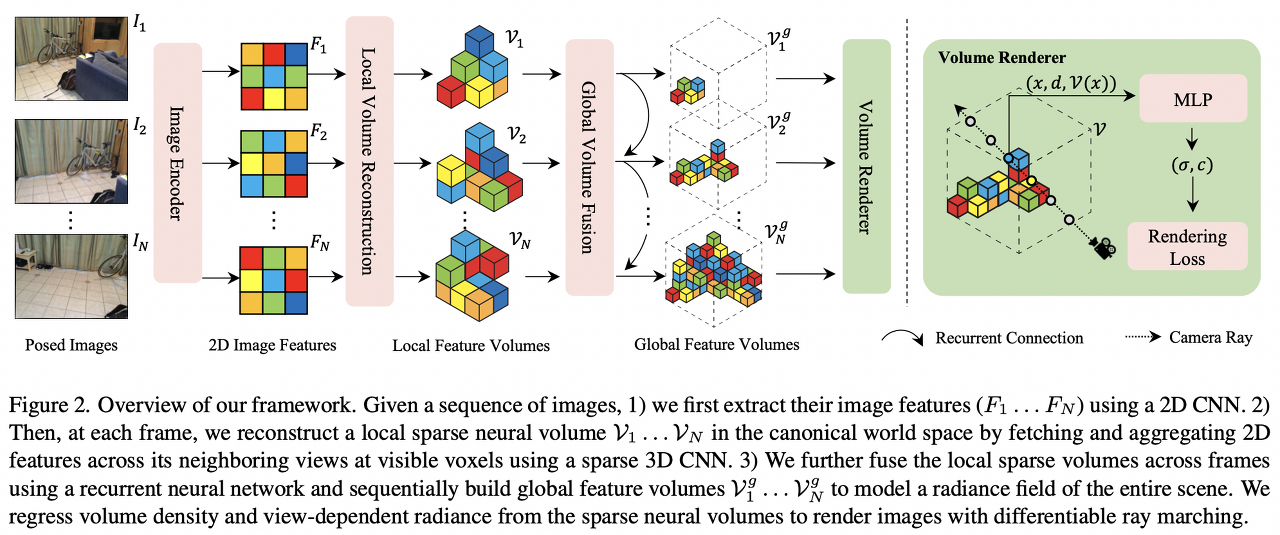
- NeRFusion (Overall)
- Sparse neural volume
- 3D Feature Volume ($\mathcal{U}_{i}$) from feature map ($F_{i}$)
- Local Volume ($\mathcal{V}_{t}$)
- Global Volume ($\mathcal{V}_{t}^{g}$)
- Fusion Module - GRU (Gated Recurrent Unit)
- 업데이트게이트 ($z_{t}$)
- 재설정게이트 ($r_{t}$)
- Voxel Pruning
- Sampling
- Direct Inference
- Training
- Pre-training across scenes
* 프로젝트에서 사용하는 라이브러리 중 vren 은 models/csrc 패키지를 라이브러리화 하여 배포한 것이기 때문에, 프로젝트 실행 전 따로 설치하여 사용해야 합니다.
NeRFusion
class NeRFusion2(nn.Module): def __init__(self, scale, grid_size=128, global_representation=None): super().__init__() # scene bounding box # TODO: this is a temp easy solution self.scale = scale self.register_buffer('center', torch.zeros(1, 3)) self.register_buffer('xyz_min', -torch.ones(1, 3)*scale) self.register_buffer('xyz_max', torch.ones(1, 3)*scale) self.register_buffer('half_size', (self.xyz_max-self.xyz_min)/2) self.grid_size = grid_size self.cascades = 1 self.register_buffer('density_bitfield', torch.ones(self.grid_size**3//8, dtype=torch.uint8)) # dummy self.register_buffer('density_grid', torch.zeros(self.cascades, self.grid_size**3)) self.register_buffer('grid_coords', create_meshgrid3d(self.grid_size, self.grid_size, self.grid_size, False, dtype=torch.int32).reshape(-1, 3)) self.global_representation = global_representation if global_representation is not None: self.initialize_global_volume(global_representation) self.xyz_encoder = \ tcnn.Network( n_input_dims=16, n_output_dims=16, network_config={ "otype": "FullyFusedMLP", "activation": "ReLU", "output_activation": "None", "n_neurons": 64, "n_hidden_layers": 1, } ) else: self.xyz_encoder = \ tcnn.NetworkWithInputEncoding( n_input_dims=3, n_output_dims=16, encoding_config={ "otype": "Grid", "type": "Dense", "n_levels": 3, "n_feature_per_level": 2, "base_resolution": 128, "per_level_scale": 2.0, "interpolation": "Linear", }, network_config={ "otype": "FullyFusedMLP", "activation": "ReLU", "output_activation": "None", "n_neurons": 64, "n_hidden_layers": 1, } ) self.dir_encoder = \ tcnn.Encoding( n_input_dims=3, encoding_config={ "otype": "SphericalHarmonics", "degree": 4, }, ) self.rgb_net = \ tcnn.Network( n_input_dims=32, n_output_dims=3, network_config={ "otype": "FullyFusedMLP", "activation": "ReLU", "output_activation": "Sigmoid", "n_neurons": 64, "n_hidden_layers": 2, } ) def density(self, x, return_feat=False): """ Inputs: x: (N, 3) xyz in [-scale, scale] return_feat: whether to return intermediate feature Outputs: sigmas: (N) """ x = (x-self.xyz_min)/(self.xyz_max-self.xyz_min) h = self.xyz_encoder(x) sigmas = TruncExp.apply(h[:, 0]) if return_feat: return sigmas, h return sigmas def forward(self, x, d, **kwargs): """ Inputs: x: (N, 3) xyz in [-scale, scale] d: (N, 3) directions Outputs: sigmas: (N) rgbs: (N, 3) """ if self.global_representation is not None: x = self.get_global_feature(x) sigmas, h = self.density(x, return_feat=True) d = d/torch.norm(d, dim=1, keepdim=True) d = self.dir_encoder((d+1)/2) rgbs = self.rgb_net(torch.cat([d, h], 1)) return sigmas, rgbs @torch.no_grad() def get_all_cells(self): """ Get all cells from the density grid. Outputs: cells: list (of length self.cascades) of indices and coords selected at each cascade """ indices = vren.morton3D(self.grid_coords).long() cells = [(indices, self.grid_coords)] * self.cascades return cells @torch.no_grad() def sample_uniform_and_occupied_cells(self, M, density_threshold): """ Sample both M uniform and occupied cells (per cascade) occupied cells are sample from cells with density > @density_threshold Outputs: cells: list (of length self.cascades) of indices and coords selected at each cascade """ cells = [] for c in range(self.cascades): # uniform cells coords1 = torch.randint(self.grid_size, (M, 3), dtype=torch.int32, device=self.density_grid.device) indices1 = vren.morton3D(coords1).long() # occupied cells indices2 = torch.nonzero(self.density_grid[c] > density_threshold)[:, 0] if len(indices2) > 0: rand_idx = torch.randint(len(indices2), (M,), device=self.density_grid.device) indices2 = indices2[rand_idx] coords2 = vren.morton3D_invert(indices2.int()) # concatenate cells += [(torch.cat([indices1, indices2]), torch.cat([coords1, coords2]))] return cells @torch.no_grad() def prune_cells(self, K, poses, img_wh, chunk=64 ** 3): """ mark the cells that aren't covered by the cameras with density -1 only executed once before training starts Inputs: K: (3, 3) camera intrinsics poses: (N, 3, 4) camera to world poses img_wh: image width and height chunk: the chunk size to split the cells (to avoid OOM) """ N_cams = poses.shape[0] self.count_grid = torch.zeros_like(self.density_grid) w2c_R = rearrange(poses[:, :3, :3], 'n a b -> n b a') # (N_cams, 3, 3) w2c_T = -w2c_R @ poses[:, :3, 3:] # (N_cams, 3, 1) cells = self.get_all_cells() for c in range(self.cascades): indices, coords = cells[c] for i in range(0, len(indices), chunk): xyzs = coords[i:i + chunk] / (self.grid_size - 1) * 2 - 1 s = min(2 ** (c - 1), self.scale) half_grid_size = s / self.grid_size xyzs_w = (xyzs * (s - half_grid_size)).T # (3, chunk) xyzs_c = w2c_R @ xyzs_w + w2c_T # (N_cams, 3, chunk) uvd = K @ xyzs_c # (N_cams, 3, chunk) uv = uvd[:, :2] / uvd[:, 2:] # (N_cams, 2, chunk) in_image = (uvd[:, 2] >= 0) & \ (uv[:, 0] >= 0) & (uv[:, 0] < img_wh[0]) & \ (uv[:, 1] >= 0) & (uv[:, 1] < img_wh[1]) covered_by_cam = (uvd[:, 2] >= NEAR_DISTANCE) & in_image # (N_cams, chunk) # if the cell is visible by at least one camera self.count_grid[c, indices[i:i + chunk]] = \ count = covered_by_cam.sum(0) / N_cams too_near_to_cam = (uvd[:, 2] < NEAR_DISTANCE) & in_image # (N, chunk) # if the cell is too close (in front) to any camera too_near_to_any_cam = too_near_to_cam.any(0) # a valid cell should be visible by at least one camera and not too close to any camera valid_mask = (count > 0) & (~too_near_to_any_cam) self.density_grid[c, indices[i:i + chunk]] = \ torch.where(valid_mask, 0., -1.) @torch.no_grad() def update_density_grid(self, density_threshold, warmup=False, decay=0.95, erode=False): density_grid_tmp = torch.zeros_like(self.density_grid) if warmup: # during the first steps cells = self.get_all_cells() else: cells = self.sample_uniform_and_occupied_cells(self.grid_size ** 3 // 4, density_threshold) # infer sigmas for c in range(self.cascades): indices, coords = cells[c] s = min(2 ** (c - 1), self.scale) half_grid_size = s / self.grid_size xyzs_w = (coords / (self.grid_size - 1) * 2 - 1) * (s - half_grid_size) # pick random position in the cell by adding noise in [-hgs, hgs] xyzs_w += (torch.rand_like(xyzs_w) * 2 - 1) * half_grid_size density_grid_tmp[c, indices] = self.density(xyzs_w) if erode: # My own logic. decay more the cells that are visible to few cameras decay = torch.clamp(decay ** (1 / self.count_grid), 0.1, 0.95) self.density_grid = \ torch.where(self.density_grid < 0, self.density_grid, torch.maximum(self.density_grid * decay, density_grid_tmp)) mean_density = self.density_grid[self.density_grid > 0].mean().item() vren.packbits(self.density_grid, min(mean_density, density_threshold), self.density_bitfield)Sparse Neural Volume
Voxel 만드는 과정
- a
class SPVCNN(nn.Module): def __init__(self, **kwargs): super().__init__() self.dropout = kwargs['dropout'] cr = kwargs.get('cr', 1.0) cs = [32, 64, 128, 96, 96] cs = [int(cr * x) for x in cs] if 'pres' in kwargs and 'vres' in kwargs: self.pres = kwargs['pres'] self.vres = kwargs['vres'] self.stem = nn.Sequential( spnn.Conv3d(kwargs['in_channels'], cs[0], kernel_size=3, stride=1), spnn.BatchNorm(cs[0]), spnn.ReLU(True) ) self.stage1 = nn.Sequential( BasicConvolutionBlock(cs[0], cs[0], ks=2, stride=2, dilation=1), ResidualBlock(cs[0], cs[1], ks=3, stride=1, dilation=1), ResidualBlock(cs[1], cs[1], ks=3, stride=1, dilation=1), ) self.stage2 = nn.Sequential( BasicConvolutionBlock(cs[1], cs[1], ks=2, stride=2, dilation=1), ResidualBlock(cs[1], cs[2], ks=3, stride=1, dilation=1), ResidualBlock(cs[2], cs[2], ks=3, stride=1, dilation=1), ) self.up1 = nn.ModuleList([ BasicDeconvolutionBlock(cs[2], cs[3], ks=2, stride=2), nn.Sequential( ResidualBlock(cs[3] + cs[1], cs[3], ks=3, stride=1, dilation=1), ResidualBlock(cs[3], cs[3], ks=3, stride=1, dilation=1), ) ]) self.up2 = nn.ModuleList([ BasicDeconvolutionBlock(cs[3], cs[4], ks=2, stride=2), nn.Sequential( ResidualBlock(cs[4] + cs[0], cs[4], ks=3, stride=1, dilation=1), ResidualBlock(cs[4], cs[4], ks=3, stride=1, dilation=1), ) ]) self.point_transforms = nn.ModuleList([ nn.Sequential( nn.Linear(cs[0], cs[2]), nn.BatchNorm1d(cs[2]), nn.ReLU(True), ), nn.Sequential( nn.Linear(cs[2], cs[4]), nn.BatchNorm1d(cs[4]), nn.ReLU(True), ) ]) self.weight_initialization() if self.dropout: self.dropout = nn.Dropout(0.3, True) def weight_initialization(self): for m in self.modules(): if isinstance(m, nn.BatchNorm1d): nn.init.constant_(m.weight, 1) nn.init.constant_(m.bias, 0) def forward(self, z): # x: SparseTensor z: PointTensor x0 = initial_voxelize(z, self.pres, self.vres) x0 = self.stem(x0) z0 = voxel_to_point(x0, z, nearest=False) z0.F = z0.F x1 = point_to_voxel(x0, z0) x1 = self.stage1(x1) x2 = self.stage2(x1) z1 = voxel_to_point(x2, z0) z1.F = z1.F + self.point_transforms[0](z0.F) y3 = point_to_voxel(x2, z1) if self.dropout: y3.F = self.dropout(y3.F) y3 = self.up1[0](y3) y3 = torchsparse.cat([y3, x1]) y3 = self.up1[1](y3) y4 = self.up2[0](y3) y4 = torchsparse.cat([y4, x0]) y4 = self.up2[1](y4) z3 = voxel_to_point(y4, z1) z3.F = z3.F + self.point_transforms[1](z1.F) return z3.F# z: PointTensor # return: SparseTensor def initial_voxelize(z, init_res, after_res): new_float_coord = torch.cat( [(z.C[:, :3] * init_res) / after_res, z.C[:, -1].view(-1, 1)], 1) pc_hash = F.sphash(torch.floor(new_float_coord).int()) sparse_hash = torch.unique(pc_hash) idx_query = F.sphashquery(pc_hash, sparse_hash) counts = F.spcount(idx_query.int(), len(sparse_hash)) inserted_coords = F.spvoxelize(torch.floor(new_float_coord), idx_query, counts) inserted_coords = torch.round(inserted_coords).int() inserted_feat = F.spvoxelize(z.F, idx_query, counts) new_tensor = SparseTensor(inserted_feat, inserted_coords, 1) new_tensor.cmaps.setdefault(new_tensor.stride, new_tensor.coords) z.additional_features['idx_query'][1] = idx_query z.additional_features['counts'][1] = counts z.C = new_float_coord return new_tensor# x: SparseTensor, z: PointTensor # return: SparseTensor def point_to_voxel(x, z): if z.additional_features is None or z.additional_features.get('idx_query') is None\ or z.additional_features['idx_query'].get(x.s) is None: #pc_hash = hash_gpu(torch.floor(z.C).int()) pc_hash = F.sphash( torch.cat([ torch.floor(z.C[:, :3] / x.s[0]).int() * x.s[0], z.C[:, -1].int().view(-1, 1) ], 1)) sparse_hash = F.sphash(x.C) idx_query = F.sphashquery(pc_hash, sparse_hash) counts = F.spcount(idx_query.int(), x.C.shape[0]) z.additional_features['idx_query'][x.s] = idx_query z.additional_features['counts'][x.s] = counts else: idx_query = z.additional_features['idx_query'][x.s] counts = z.additional_features['counts'][x.s] inserted_feat = F.spvoxelize(z.F, idx_query, counts) new_tensor = SparseTensor(inserted_feat, x.C, x.s) new_tensor.cmaps = x.cmaps new_tensor.kmaps = x.kmaps return new_tensor# x: SparseTensor, z: PointTensor # return: PointTensor def voxel_to_point(x, z, nearest=False): if z.idx_query is None or z.weights is None or z.idx_query.get( x.s) is None or z.weights.get(x.s) is None: off = get_kernel_offsets(2, x.s, 1, device=z.F.device) #old_hash = kernel_hash_gpu(torch.floor(z.C).int(), off) old_hash = F.sphash( torch.cat([ torch.floor(z.C[:, :3] / x.s[0]).int() * x.s[0], z.C[:, -1].int().view(-1, 1) ], 1), off) pc_hash = F.sphash(x.C.to(z.F.device)) idx_query = F.sphashquery(old_hash, pc_hash) weights = F.calc_ti_weights(z.C, idx_query, scale=x.s[0]).transpose(0, 1).contiguous() idx_query = idx_query.transpose(0, 1).contiguous() if nearest: weights[:, 1:] = 0. idx_query[:, 1:] = -1 new_feat = F.spdevoxelize(x.F, idx_query, weights) new_tensor = PointTensor(new_feat, z.C, idx_query=z.idx_query, weights=z.weights) new_tensor.additional_features = z.additional_features new_tensor.idx_query[x.s] = idx_query new_tensor.weights[x.s] = weights z.idx_query[x.s] = idx_query z.weights[x.s] = weights else: new_feat = F.spdevoxelize(x.F, z.idx_query.get(x.s), z.weights.get(x.s)) new_tensor = PointTensor(new_feat, z.C, idx_query=z.idx_query, weights=z.weights) new_tensor.additional_features = z.additional_features return new_tensorclass SparseVoxelGrid(nn.Module): def __init__(self, scale, resolution, feat_dim): """ scale: range of xyz. 0.5 -> (-0.5, 0.5) resolution: #voxels within each dim. 128 -> 128x128x128 """ super().__init__() self.scale = scale self.resolution = resolution self.voxel_size = scale * 2 / resolution3D Feature Volume
class VolumeRenderer(torch.autograd.Function): """ Volume rendering with different number of samples per ray Used in training only Inputs: sigmas: (N) rgbs: (N, 3) deltas: (N) ts: (N) rays_a: (N_rays, 3) ray_idx, start_idx, N_samples meaning each entry corresponds to the @ray_idx th ray, whose samples are [start_idx:start_idx+N_samples] T_threshold: float, stop the ray if the transmittance is below it Outputs: total_samples: int, total effective samples opacity: (N_rays) depth: (N_rays) rgb: (N_rays, 3) ws: (N) sample point weights """ @staticmethod @custom_fwd(cast_inputs=torch.float32) def forward(ctx, sigmas, rgbs, deltas, ts, rays_a, T_threshold): total_samples, opacity, depth, rgb, ws = \ vren.composite_train_fw(sigmas, rgbs, deltas, ts, rays_a, T_threshold) ctx.save_for_backward(sigmas, rgbs, deltas, ts, rays_a, opacity, depth, rgb, ws) ctx.T_threshold = T_threshold return total_samples.sum(), opacity, depth, rgb, ws @staticmethod @custom_bwd def backward(ctx, dL_dtotal_samples, dL_dopacity, dL_ddepth, dL_drgb, dL_dws): sigmas, rgbs, deltas, ts, rays_a, \ opacity, depth, rgb, ws = ctx.saved_tensors dL_dsigmas, dL_drgbs = \ vren.composite_train_bw(dL_dopacity, dL_ddepth, dL_drgb, dL_dws, sigmas, rgbs, ws, deltas, ts, rays_a, opacity, depth, rgb, ctx.T_threshold) return dL_dsigmas, dL_drgbs, None, None, None, NoneFusion Module
GRU Fusion
ConvGRU를 사용하여 hidden state feature를 업데이트한다.
Update hidden state features with ConvGRU.- convert2dense:
- sparse feature를 dense feature로 바꾼다.
- [updated_coords] 현재 feature의 좌표와 이전 좌표들을 FBV에서 합친다. 이는 global hidden state로부터 new feature coordinates로 만든다.
- ground truth tsdf를 합성한다.
- update_map: Replace hidden state/tsdf in global hidden state/tsdf volume by direct substitute corresponding voxels
- save_mesh: scene & scene_tsdf
- forward (Incremental fusion)
- If the fragment is from new scene, then reinitialize backend map
- Each level has its corresponding voxel size.
- Get the relative origin in global volume.
- Convert to dense
- Convert sparse features to dense feature
- Combine current feature coordinates and previous feature coordinates within FBV from our backend map to get new feature coordinates(updated_coords)
- Dense to sparse: get feature using new feature coordinates
- Get fused ground truth
- Feed back to global volume
class GRUFusion(nn.Module): """ Two functionalities of this class: 1. GRU Fusion module as in the paper. Update hidden state features with ConvGRU. 2. Substitute TSDF in the global volume when direct_substitute = True. """ def __init__(self, cfg, ch_in=None, direct_substitute=False): super(GRUFusion, self).__init__() self.cfg = cfg # replace tsdf in global tsdf volume by direct substitute corresponding voxels self.direct_substitude = direct_substitute if direct_substitute: # tsdf self.ch_in = [1, 1, 1] self.feat_init = 1 else: # features self.ch_in = ch_in self.feat_init = 0 self.n_scales = len(cfg.THRESHOLDS) - 1 self.scene_name = [None, None, None] self.global_origin = [None, None, None] self.global_volume = [None, None, None] self.target_tsdf_volume = [None, None, None] if direct_substitute: self.fusion_nets = None else: self.fusion_nets = nn.ModuleList() for i, ch in enumerate(ch_in): self.fusion_nets.append(ConvGRU(hidden_dim=ch, input_dim=ch, pres=1, vres=self.cfg.VOXEL_SIZE * 2 ** (self.n_scales - i))) def reset(self, i): self.global_volume[i] = PointTensor(torch.Tensor([]), torch.Tensor([]).view(0, 3).long()).cuda() self.target_tsdf_volume[i] = PointTensor(torch.Tensor([]), torch.Tensor([]).view(0, 3).long()).cuda() def convert2dense(self, current_coords, current_values, coords_target_global, tsdf_target, relative_origin, scale): ''' 1. convert sparse feature to dense feature; 2. combine current feature coordinates and previous coordinates within FBV from global hidden state to get new feature coordinates (updated_coords); 3. fuse ground truth tsdf. :param current_coords: (Tensor), current coordinates, (N, 3) :param current_values: (Tensor), current features/tsdf, (N, C) :param coords_target_global: (Tensor), ground truth coordinates, (N', 3) :param tsdf_target: (Tensor), tsdf ground truth, (N',) :param relative_origin: (Tensor), origin in global volume, (3,) :param scale: :return: updated_coords: (Tensor), coordinates after combination, (N', 3) :return: current_volume: (Tensor), current dense feature/tsdf volume, (DIM_X, DIM_Y, DIM_Z, C) :return: global_volume: (Tensor), global dense feature/tsdf volume, (DIM_X, DIM_Y, DIM_Z, C) :return: target_volume: (Tensor), dense target tsdf volume, (DIM_X, DIM_Y, DIM_Z, 1) :return: valid: mask: 1 represent in current FBV (N,) :return: valid_target: gt mask: 1 represent in current FBV (N,) ''' # previous frame global_coords = self.global_volume[scale].C global_value = self.global_volume[scale].F global_tsdf_target = self.target_tsdf_volume[scale].F global_coords_target = self.target_tsdf_volume[scale].C dim = (torch.Tensor(self.cfg.N_VOX).cuda() // 2 ** (self.cfg.N_LAYER - scale - 1)).int() dim_list = dim.data.cpu().numpy().tolist() # mask voxels that are out of the FBV global_coords = global_coords - relative_origin valid = ((global_coords < dim) & (global_coords >= 0)).all(dim=-1) if self.cfg.FUSION.FULL is False: valid_volume = sparse_to_dense_torch(current_coords, 1, dim_list, 0, global_value.device) value = valid_volume[global_coords[valid][:, 0], global_coords[valid][:, 1], global_coords[valid][:, 2]] all_true = valid[valid] all_true[value == 0] = False valid[valid] = all_true # sparse to dense global_volume = sparse_to_dense_channel(global_coords[valid], global_value[valid], dim_list, self.ch_in[scale], self.feat_init, global_value.device) current_volume = sparse_to_dense_channel(current_coords, current_values, dim_list, self.ch_in[scale], self.feat_init, global_value.device) if self.cfg.FUSION.FULL is True: # change the structure of sparsity, combine current coordinates and previous coordinates from global volume if self.direct_substitude: updated_coords = torch.nonzero((global_volume.abs() < 1).any(-1) | (current_volume.abs() < 1).any(-1)) else: updated_coords = torch.nonzero((global_volume != 0).any(-1) | (current_volume != 0).any(-1)) else: updated_coords = current_coords # fuse ground truth if tsdf_target is not None: # mask voxels that are out of the FBV global_coords_target = global_coords_target - relative_origin valid_target = ((global_coords_target < dim) & (global_coords_target >= 0)).all(dim=-1) # combine current tsdf and global tsdf coords_target = torch.cat([global_coords_target[valid_target], coords_target_global])[:, :3] tsdf_target = torch.cat([global_tsdf_target[valid_target], tsdf_target.unsqueeze(-1)]) # sparse to dense target_volume = sparse_to_dense_channel(coords_target, tsdf_target, dim_list, 1, 1, tsdf_target.device) else: target_volume = valid_target = None return updated_coords, current_volume, global_volume, target_volume, valid, valid_target def update_map(self, value, coords, target_volume, valid, valid_target, relative_origin, scale): ''' Replace Hidden state/tsdf in global Hidden state/tsdf volume by direct substitute corresponding voxels :param value: (Tensor) fused feature (N, C) :param coords: (Tensor) updated coords (N, 3) :param target_volume: (Tensor) tsdf volume (DIM_X, DIM_Y, DIM_Z, 1) :param valid: (Tensor) mask: 1 represent in current FBV (N,) :param valid_target: (Tensor) gt mask: 1 represent in current FBV (N,) :param relative_origin: (Tensor), origin in global volume, (3,) :param scale: :return: ''' # pred self.global_volume[scale].F = torch.cat( [self.global_volume[scale].F[valid == False], value]) coords = coords + relative_origin self.global_volume[scale].C = torch.cat([self.global_volume[scale].C[valid == False], coords]) # target if target_volume is not None: target_volume = target_volume.squeeze() self.target_tsdf_volume[scale].F = torch.cat( [self.target_tsdf_volume[scale].F[valid_target == False], target_volume[target_volume.abs() < 1].unsqueeze(-1)]) target_coords = torch.nonzero(target_volume.abs() < 1) + relative_origin self.target_tsdf_volume[scale].C = torch.cat( [self.target_tsdf_volume[scale].C[valid_target == False], target_coords]) def save_mesh(self, scale, outputs, scene): if outputs is None: outputs = dict() if "scene_name" not in outputs: outputs['origin'] = [] outputs['scene_tsdf'] = [] outputs['scene_name'] = [] # only keep the newest result if scene in outputs['scene_name']: # delete old idx = outputs['scene_name'].index(scene) del outputs['origin'][idx] del outputs['scene_tsdf'][idx] del outputs['scene_name'][idx] # scene name outputs['scene_name'].append(scene) fuse_coords = self.global_volume[scale].C tsdf = self.global_volume[scale].F.squeeze(-1) max_c = torch.max(fuse_coords, dim=0)[0][:3] min_c = torch.min(fuse_coords, dim=0)[0][:3] outputs['origin'].append(min_c * self.cfg.VOXEL_SIZE * (2 ** (self.cfg.N_LAYER - scale - 1))) ind_coords = fuse_coords - min_c dim_list = (max_c - min_c + 1).int().data.cpu().numpy().tolist() tsdf_volume = sparse_to_dense_torch(ind_coords, tsdf, dim_list, 1, tsdf.device) outputs['scene_tsdf'].append(tsdf_volume) return outputs def forward(self, coords, values_in, inputs, scale=2, outputs=None, save_mesh=False): ''' :param coords: (Tensor), coordinates of voxels, (N, 4) (4 : Batch ind, x, y, z) :param values_in: (Tensor), features/tsdf, (N, C) :param inputs: dict: meta data from dataloader :param scale: :param outputs: :param save_mesh: a bool to indicate whether or not to save the reconstructed mesh of current sample if direct_substitude: :return: outputs: dict: { 'origin': (List), origin of the predicted partial volume, [3] 'scene_tsdf': (List), predicted tsdf volume, [(nx, ny, nz)] 'target': (List), ground truth tsdf volume, [(nx', ny', nz')] 'scene_name': (List), name of each scene in 'scene_tsdf', [string] } else: :return: updated_coords_all: (Tensor), updated coordinates, (N', 4) (4 : Batch ind, x, y, z) :return: values_all: (Tensor), features after gru fusion, (N', C) :return: tsdf_target_all: (Tensor), tsdf ground truth, (N', 1) :return: occ_target_all: (Tensor), occupancy ground truth, (N', 1) ''' if self.global_volume[scale] is not None: # delete computational graph to save memory self.global_volume[scale] = self.global_volume[scale].detach() batch_size = len(inputs['fragment']) interval = 2 ** (self.cfg.N_LAYER - scale - 1) tsdf_target_all = None occ_target_all = None values_all = None updated_coords_all = None # ---incremental fusion---- for i in range(batch_size): scene = inputs['scene'][i] # scene name global_origin = inputs['vol_origin'][i] # origin of global volume origin = inputs['vol_origin_partial'][i] # origin of part volume if scene != self.scene_name[scale] and self.scene_name[scale] is not None and self.direct_substitude: outputs = self.save_mesh(scale, outputs, self.scene_name[scale]) # if this fragment is from new scene, we reinitialize backend map if self.scene_name[scale] is None or scene != self.scene_name[scale]: self.scene_name[scale] = scene self.reset(scale) self.global_origin[scale] = global_origin # each level has its corresponding voxel size voxel_size = self.cfg.VOXEL_SIZE * interval # relative origin in global volume relative_origin = (origin - self.global_origin[scale]) / voxel_size relative_origin = relative_origin.cuda().long() batch_ind = torch.nonzero(coords[:, 0] == i).squeeze(1) if len(batch_ind) == 0: continue coords_b = coords[batch_ind, 1:].long() // interval values = values_in[batch_ind] if 'occ_list' in inputs.keys(): # get partial gt occ_target = inputs['occ_list'][self.cfg.N_LAYER - scale - 1][i] tsdf_target = inputs['tsdf_list'][self.cfg.N_LAYER - scale - 1][i][occ_target] coords_target = torch.nonzero(occ_target) else: coords_target = tsdf_target = None # convert to dense: 1. convert sparse feature to dense feature; 2. combine current feature coordinates and # previous feature coordinates within FBV from our backend map to get new feature coordinates (updated_coords) updated_coords, current_volume, global_volume, target_volume, valid, valid_target = self.convert2dense( coords_b, values, coords_target, tsdf_target, relative_origin, scale) # dense to sparse: get features using new feature coordinates (updated_coords) values = current_volume[updated_coords[:, 0], updated_coords[:, 1], updated_coords[:, 2]] global_values = global_volume[updated_coords[:, 0], updated_coords[:, 1], updated_coords[:, 2]] # get fused gt if target_volume is not None: tsdf_target = target_volume[updated_coords[:, 0], updated_coords[:, 1], updated_coords[:, 2]] occ_target = tsdf_target.abs() < 1 else: tsdf_target = occ_target = None if not self.direct_substitude: # convert to aligned camera coordinate r_coords = updated_coords.detach().clone().float() r_coords = r_coords.permute(1, 0).contiguous().float() * voxel_size + origin.unsqueeze(-1).float() r_coords = torch.cat((r_coords, torch.ones_like(r_coords[:1])), dim=0) r_coords = inputs['world_to_aligned_camera'][i, :3, :] @ r_coords r_coords = torch.cat([r_coords, torch.zeros(1, r_coords.shape[-1]).to(r_coords.device)]) r_coords = r_coords.permute(1, 0).contiguous() h = PointTensor(global_values, r_coords) x = PointTensor(values, r_coords) values = self.fusion_nets[scale](h, x) # feed back to global volume (direct substitute) self.update_map(values, updated_coords, target_volume, valid, valid_target, relative_origin, scale) if updated_coords_all is None: updated_coords_all = torch.cat([torch.ones_like(updated_coords[:, :1]) * i, updated_coords * interval], dim=1) values_all = values tsdf_target_all = tsdf_target occ_target_all = occ_target else: updated_coords = torch.cat([torch.ones_like(updated_coords[:, :1]) * i, updated_coords * interval], dim=1) updated_coords_all = torch.cat([updated_coords_all, updated_coords]) values_all = torch.cat([values_all, values]) if tsdf_target_all is not None: tsdf_target_all = torch.cat([tsdf_target_all, tsdf_target]) occ_target_all = torch.cat([occ_target_all, occ_target]) if self.direct_substitude and save_mesh: outputs = self.save_mesh(scale, outputs, self.scene_name[scale]) if self.direct_substitude: return outputs else: return updated_coords_all, values_all, tsdf_target_all, occ_target_allConvGRU
$$z_{t} = M_{z} \left( \left[ \mathcal{V}^{g}_{t-1} , \mathcal{V}_{t} \right] \right)$$$$r_{t} = M_{r} \left( \left[ \mathcal{V}^{g}_{t-1} , \mathcal{V}_{t} \right] \right)$$$${\overset{\sim}{\mathcal{V}}}_{t}^{g} = M_{t} \left( \left[ r_{t} * \mathcal{V}^{g}_{t-1} , \mathcal{V}_{t} \right] \right)$$$$\mathcal{V}_{t}^{g} = (1 - z_{t} ) * \mathcal{V}^{g}_{t-1} + z_{t} * {\overset{\sim}{\mathcal{V}}}_{t}^{g} $$
- $M_{z}, M_{r}$는 (업데이트게이트($z_{t}$), 재설정게이트($r_{t}$)를 위한 희소 3D Conv Layer) sigmoid 활성화 함수 사용
- $M_{t}$는 tanh 활성화 함수 사용
class ConvGRU(nn.Module): def __init__(self, hidden_dim=128, input_dim=192 + 128, pres=1, vres=1): super(ConvGRU, self).__init__() self.convz = SConv3d(hidden_dim + input_dim, hidden_dim, pres, vres, 3) self.convr = SConv3d(hidden_dim + input_dim, hidden_dim, pres, vres, 3) self.convq = SConv3d(hidden_dim + input_dim, hidden_dim, pres, vres, 3) def forward(self, h, x): ''' :param h: PintTensor :param x: PintTensor :return: h.F: Tensor (N, C) ''' hx = PointTensor(torch.cat([h.F, x.F], dim=1), h.C) z = torch.sigmoid(self.convz(hx).F) r = torch.sigmoid(self.convr(hx).F) x.F = torch.cat([r * h.F, x.F], dim=1) q = torch.tanh(self.convq(x).F) h.F = (1 - z) * h.F + z * q return h.FSparse 3D Conv Layer
import torchsparse.nn as spnn class SConv3d(nn.Module): def __init__(self, inc, outc, pres, vres, ks=3, stride=1, dilation=1): super().__init__() self.net = spnn.Conv3d(inc, outc, kernel_size=ks, dilation=dilation, stride=stride) self.point_transforms = nn.Sequential( nn.Linear(inc, outc), ) self.pres = pres self.vres = vres def forward(self, z): x = initial_voxelize(z, self.pres, self.vres) x = self.net(x) out = voxel_to_point(x, z, nearest=False) out.F = out.F + self.point_transforms(z.F) return outdef sparse_to_dense_torch(locs, values, dim, default_val, device): dense = torch.full([dim[0], dim[1], dim[2]], float(default_val), device=device) if locs.shape[0] > 0: dense[locs[:, 0], locs[:, 1], locs[:, 2]] = values return dense def sparse_to_dense_channel(locs, values, dim, c, default_val, device): dense = torch.full([dim[0], dim[1], dim[2], c], float(default_val), device=device) if locs.shape[0] > 0: dense[locs[:, 0], locs[:, 1], locs[:, 2]] = values return denseUpdate Density Grid
복셀을 계산한 결과에 따라 주변 복셀(density)을 업데이트 시켜준다. training_step에서 설정한 update_interval마다 실행된다.
더보기def training_step(self, batch, batch_nb, *args): if self.global_step%self.update_interval == 0: self.model.update_density_grid(0.01*MAX_SAMPLES/3**0.5, warmup=self.global_step<self.warmup_steps, erode=self.hparams.dataset_name=='colmap') results = self(batch, split='train') loss_d = self.loss(results, batch) loss = sum(lo.mean() for lo in loss_d.values()) with torch.no_grad(): self.train_psnr(results['rgb'], batch['rgb']) self.log('lr', self.net_opt.param_groups[0]['lr']) self.log('train/loss', loss) # ray marching samples per ray (occupied space on the ray) self.log('train/rm_s', results['rm_samples']/len(batch['rgb']), True) # volume rendering samples per ray (stops marching when transmittance drops below 1e-4) self.log('train/vr_s', results['vr_samples']/len(batch['rgb']), True) self.log('train/psnr', self.train_psnr, True) return loss@torch.no_grad() def update_density_grid(self, density_threshold, warmup=False, decay=0.95, erode=False): density_grid_tmp = torch.zeros_like(self.density_grid) if warmup: # during the first steps cells = self.get_all_cells() else: cells = self.sample_uniform_and_occupied_cells(self.grid_size ** 3 // 4, density_threshold) # infer sigmas for c in range(self.cascades): indices, coords = cells[c] s = min(2 ** (c - 1), self.scale) half_grid_size = s / self.grid_size xyzs_w = (coords / (self.grid_size - 1) * 2 - 1) * (s - half_grid_size) # pick random position in the cell by adding noise in [-hgs, hgs] xyzs_w += (torch.rand_like(xyzs_w) * 2 - 1) * half_grid_size density_grid_tmp[c, indices] = self.density(xyzs_w) if erode: # My own logic. decay more the cells that are visible to few cameras decay = torch.clamp(decay ** (1 / self.count_grid), 0.1, 0.95) self.density_grid = \ torch.where(self.density_grid < 0, self.density_grid, torch.maximum(self.density_grid * decay, density_grid_tmp)) mean_density = self.density_grid[self.density_grid > 0].mean().item() vren.packbits(self.density_grid, min(mean_density, density_threshold), self.density_bitfield)Backbone (MNAS)
class MnasMulti(nn.Module): def __init__(self, alpha=1.0): super(MnasMulti, self).__init__() depths = _get_depths(alpha) if alpha == 1.0: MNASNet = torchvision.models.mnasnet1_0(pretrained=True, progress=True) else: MNASNet = torchvision.models.MNASNet(alpha=alpha) self.conv0 = nn.Sequential( MNASNet.layers._modules['0'], MNASNet.layers._modules['1'], MNASNet.layers._modules['2'], MNASNet.layers._modules['3'], MNASNet.layers._modules['4'], MNASNet.layers._modules['5'], MNASNet.layers._modules['6'], MNASNet.layers._modules['7'], MNASNet.layers._modules['8'], ) self.conv1 = MNASNet.layers._modules['9'] self.conv2 = MNASNet.layers._modules['10'] self.out1 = nn.Conv2d(depths[4], depths[4], 1, bias=False) self.out_channels = [depths[4]] final_chs = depths[4] self.inner1 = nn.Conv2d(depths[3], final_chs, 1, bias=True) self.inner2 = nn.Conv2d(depths[2], final_chs, 1, bias=True) self.out2 = nn.Conv2d(final_chs, depths[3], 3, padding=1, bias=False) self.out3 = nn.Conv2d(final_chs, depths[2], 3, padding=1, bias=False) self.out_channels.append(depths[3]) self.out_channels.append(depths[2]) def forward(self, x): conv0 = self.conv0(x) conv1 = self.conv1(conv0) conv2 = self.conv2(conv1) intra_feat = conv2 outputs = [] out = self.out1(intra_feat) outputs.append(out) intra_feat = F.interpolate(intra_feat, scale_factor=2, mode="nearest") + self.inner1(conv1) out = self.out2(intra_feat) outputs.append(out) intra_feat = F.interpolate(intra_feat, scale_factor=2, mode="nearest") + self.inner2(conv0) out = self.out3(intra_feat) outputs.append(out) return outputs[::-1]Voxel Pruning
NeRFusion2의 method
@torch.no_grad() def prune_cells(self, K, poses, img_wh, chunk=64 ** 3): """ mark the cells that aren't covered by the cameras with density -1 only executed once before training starts Inputs: K: (3, 3) camera intrinsics poses: (N, 3, 4) camera to world poses img_wh: image width and height chunk: the chunk size to split the cells (to avoid OOM) """ N_cams = poses.shape[0] self.count_grid = torch.zeros_like(self.density_grid) w2c_R = rearrange(poses[:, :3, :3], 'n a b -> n b a') # (N_cams, 3, 3) w2c_T = -w2c_R @ poses[:, :3, 3:] # (N_cams, 3, 1) cells = self.get_all_cells() for c in range(self.cascades): indices, coords = cells[c] for i in range(0, len(indices), chunk): xyzs = coords[i:i + chunk] / (self.grid_size - 1) * 2 - 1 s = min(2 ** (c - 1), self.scale) half_grid_size = s / self.grid_size xyzs_w = (xyzs * (s - half_grid_size)).T # (3, chunk) xyzs_c = w2c_R @ xyzs_w + w2c_T # (N_cams, 3, chunk) uvd = K @ xyzs_c # (N_cams, 3, chunk) uv = uvd[:, :2] / uvd[:, 2:] # (N_cams, 2, chunk) in_image = (uvd[:, 2] >= 0) & \ (uv[:, 0] >= 0) & (uv[:, 0] < img_wh[0]) & \ (uv[:, 1] >= 0) & (uv[:, 1] < img_wh[1]) covered_by_cam = (uvd[:, 2] >= NEAR_DISTANCE) & in_image # (N_cams, chunk) # if the cell is visible by at least one camera self.count_grid[c, indices[i:i + chunk]] = \ count = covered_by_cam.sum(0) / N_cams too_near_to_cam = (uvd[:, 2] < NEAR_DISTANCE) & in_image # (N, chunk) # if the cell is too close (in front) to any camera too_near_to_any_cam = too_near_to_cam.any(0) # a valid cell should be visible by at least one camera and not too close to any camera valid_mask = (count > 0) & (~too_near_to_any_cam) self.density_grid[c, indices[i:i + chunk]] = \ torch.where(valid_mask, 0., -1.)Sampling
# https://github.com/zju3dv/NeuralRecon/blob/master/ops/generate_grids.py def generate_grid(n_vox, interval): with torch.no_grad(): # Create voxel grid grid_range = [torch.arange(0, n_vox[axis], interval) for axis in range(3)] grid = torch.stack(torch.meshgrid(grid_range[0], grid_range[1], grid_range[2])) # 3 dx dy dz grid = grid.unsqueeze(0).cuda().float() # 1 3 dx dy dz grid = grid.view(1, 3, -1) return gridDirect Inference
Render (2)
@torch.cuda.amp.autocast() def render(model, rays_o, rays_d, **kwargs): """ Render rays by 1. Compute the intersection of the rays with the scene bounding box 2. Follow the process in @render_func (different for train/test) Inputs: model: rays_o: (N_rays, 3) ray origins rays_d: (N_rays, 3) ray directions Outputs: result: dictionary containing final rgb and depth """ rays_o = rays_o.contiguous(); rays_d = rays_d.contiguous() hits_cnt, hits_t, hits_voxel_idx = \ RayAABBIntersector.apply(rays_o, rays_d, model.center, model.half_size, 1) # 최소 거리 near로 고정 hits_t[(hits_t[:, 0, 0]>=0)&(hits_t[:, 0, 0]<NEAR_DISTANCE), 0, 0] = NEAR_DISTANCE # hits_t == -1 if there's no hit # (N_rays, max_hits, 2) render_func = __render_rays_test if kwargs.get('test_time', False) else __render_rays_train results = render_func(model, rays_o, rays_d, hits_t, **kwargs) for k, v in results.items(): if kwargs.get('to_cpu', False): v = v.cpu() if kwargs.get('to_numpy', False): v = v.numpy() results[k] = v return resultsCompute Intersection (2-1)
Compute intersection of the rays with the scene bounding box (axis-aligned voxles).
class RayAABBIntersector(torch.autograd.Function): """ Computes the intersections of rays and axis-aligned voxels. Inputs: rays_o: (N_rays, 3) ray origins rays_d: (N_rays, 3) ray directions centers: (N_voxels, 3) voxel centers half_sizes: (N_voxels, 3) voxel half sizes max_hits: maximum number of intersected voxels to keep for one ray (for a cubic scene, this is at most 3*N_voxels^(1/3)-2) Outputs: hits_cnt: (N_rays) number of hits for each ray (followings are from near to far) hits_t: (N_rays, max_hits, 2) hit t's (-1 if no hit) hits_voxel_idx: (N_rays, max_hits) hit voxel indices (-1 if no hit) """ @staticmethod @custom_fwd(cast_inputs=torch.float32) def forward(ctx, rays_o, rays_d, center, half_size, max_hits): return vren.ray_aabb_intersect(rays_o, rays_d, center, half_size, max_hits)Render [Train] (2-2)
- [RayMarcher.apply()] 레이 마칭을 레이의 방향을 따라 진행한다. 밀도의 비트영역에 빈 공간을 뺀 영역을 쿼리해주고 유효한 샘플 포인트들을 얻는다.
March the rays along their directions, querying density bitfield to skip empty space, and get the effective sample points (where there is object). - [model(xyzs, dirs, **kwargs)] NN을 샘플링한 포인트와 뷰방향에 대해 추론해주고 properties(density, rgbs)를 추론한다.
Infer the NN at these positions and view directions to get properties (currently sigmas and rgbs). - [VolumeRenderer.apply()] 볼륨을 렌더링하여 결과를 합친다 (앞뒤로 합치고 투과율이 경계값 이하가 되면 멈춘다).
Use volume rendering to combine the result (front to back compositing and early stop the ray if its transmittance is below a threshold).
def __render_rays_train(model, rays_o, rays_d, hits_t, **kwargs): exp_step_factor = kwargs.get('exp_step_factor', 0.) results = {} (rays_a, xyzs, dirs, results['deltas'], results['ts'], results['rm_samples']) = \ RayMarcher.apply( rays_o, rays_d, hits_t[:, 0], model.density_bitfield, model.cascades, model.scale, exp_step_factor, model.grid_size, MAX_SAMPLES) for k, v in kwargs.items(): # supply additional inputs, repeated per ray if isinstance(v, torch.Tensor): kwargs[k] = torch.repeat_interleave(v[rays_a[:, 0]], rays_a[:, 2], 0) # rays_a: (N_rays, 3) ray_idx, start_idx, N_samples sigmas, rgbs = model(xyzs, dirs, **kwargs) (results['vr_samples'], results['opacity'], results['depth'], results['rgb'], results['ws']) = \ VolumeRenderer.apply(sigmas, rgbs, results['deltas'], results['ts'], rays_a, kwargs.get('T_threshold', 1e-4)) results['rays_a'] = rays_a if exp_step_factor==0: # synthetic rgb_bg = torch.ones(3, device=rays_o.device) else: # real if kwargs.get('random_bg', False): rgb_bg = torch.rand(3, device=rays_o.device) else: rgb_bg = torch.zeros(3, device=rays_o.device) results['rgb'] = results['rgb'] + \ rgb_bg*rearrange(1-results['opacity'], 'n -> n 1') return resultsRender [Test] (2-2)
@torch.no_grad() def __render_rays_test(model, rays_o, rays_d, hits_t, **kwargs): """ Render rays by while (a ray hasn't converged) 1. Move each ray to its next occupied @N_samples (initially 1) samples and evaluate the properties (sigmas, rgbs) there 2. Composite the result to output; if a ray has transmittance lower than a threshold, mark this ray as converged and stop marching it. When more rays are dead, we can increase the number of samples of each marching (the variable @N_samples) """ exp_step_factor = kwargs.get('exp_step_factor', 0.) results = {} # output tensors to be filled in N_rays = len(rays_o) device = rays_o.device opacity = torch.zeros(N_rays, device=device) depth = torch.zeros(N_rays, device=device) rgb = torch.zeros(N_rays, 3, device=device) samples = total_samples = 0 alive_indices = torch.arange(N_rays, device=device) # if it's synthetic data, bg is majority so min_samples=1 effectively covers the bg # otherwise, 4 is more efficient empirically min_samples = 1 if exp_step_factor==0 else 4 while samples < kwargs.get('max_samples', MAX_SAMPLES): N_alive = len(alive_indices) if N_alive==0: break # the number of samples to add on each ray N_samples = max(min(N_rays//N_alive, 64), min_samples) samples += N_samples xyzs, dirs, deltas, ts, N_eff_samples = \ vren.raymarching_test(rays_o, rays_d, hits_t[:, 0], alive_indices, model.density_bitfield, model.cascades, model.scale, exp_step_factor, model.grid_size, MAX_SAMPLES, N_samples) total_samples += N_eff_samples.sum() xyzs = rearrange(xyzs, 'n1 n2 c -> (n1 n2) c') dirs = rearrange(dirs, 'n1 n2 c -> (n1 n2) c') valid_mask = ~torch.all(dirs==0, dim=1) if valid_mask.sum()==0: break sigmas = torch.zeros(len(xyzs), device=device) rgbs = torch.zeros(len(xyzs), 3, device=device) sigmas[valid_mask], _rgbs = model(xyzs[valid_mask], dirs[valid_mask], **kwargs) rgbs[valid_mask] = _rgbs.float() sigmas = rearrange(sigmas, '(n1 n2) -> n1 n2', n2=N_samples) rgbs = rearrange(rgbs, '(n1 n2) c -> n1 n2 c', n2=N_samples) vren.composite_test_fw( sigmas, rgbs, deltas, ts, hits_t[:, 0], alive_indices, kwargs.get('T_threshold', 1e-4), N_eff_samples, opacity, depth, rgb) alive_indices = alive_indices[alive_indices>=0] # remove converged rays results['opacity'] = opacity results['depth'] = depth results['rgb'] = rgb results['total_samples'] = total_samples # total samples for all rays if exp_step_factor==0: # synthetic rgb_bg = torch.ones(3, device=device) else: # real rgb_bg = torch.zeros(3, device=device) results['rgb'] += rgb_bg*rearrange(1-opacity, 'n -> n 1') return resultsRay Marcher (2-2-1)
레이마칭(vren.raymarching_train)하여 샘플링된 지점의 위치와 방향 가져오기.
Outputs
- rays_a: (N_rays) - ray_idx, start_idx, N_samples
- xyzs: (N, 3) position of samples
- dirs: (N, 3) view direction of samples
- deltas: (N) $d_{t}$ for integration (복셀 내부의 충돌지점의 거리 t~t+1 사이의 간격)
- ts: (N) t of samples (복셀 내부의 충돌지점의 거리)
class RayMarcher(torch.autograd.Function): """ March the rays to get sample point positions and directions. Inputs: rays_o: (N_rays, 3) ray origins rays_d: (N_rays, 3) normalized ray directions hits_t: (N_rays, 2) near and far bounds from aabb intersection density_bitfield: (C*G**3//8) cascades: int scale: float exp_step_factor: the exponential factor to scale the steps grid_size: int max_samples: int Outputs: rays_a: (N_rays) ray_idx, start_idx, N_samples xyzs: (N, 3) sample positions # (t와 d를 통해 o + t*d 계산한 위치) dirs: (N, 3) sample view directions deltas: (N) dt for integration #(복셀 내부의 충돌 지점(t, t+1)의 간격) ts: (N) sample ts #(복샐 내부의 충돌지점==거리(t) 모임) """ @staticmethod @custom_fwd(cast_inputs=torch.float32) def forward(ctx, rays_o, rays_d, hits_t, density_bitfield, cascades, scale, exp_step_factor, grid_size, max_samples): # noise to perturb the first sample of each ray noise = torch.rand_like(rays_o[:, 0]) rays_a, xyzs, dirs, deltas, ts, counter = \ vren.raymarching_train( rays_o, rays_d, hits_t, density_bitfield, cascades, scale, exp_step_factor, noise, grid_size, max_samples) total_samples = counter[0] # total samples for all rays # remove redundant output xyzs = xyzs[:total_samples] dirs = dirs[:total_samples] deltas = deltas[:total_samples] ts = ts[:total_samples] ctx.save_for_backward(rays_a, ts) return rays_a, xyzs, dirs, deltas, ts, total_samples @staticmethod @custom_bwd def backward(ctx, dL_drays_a, dL_dxyzs, dL_ddirs, dL_ddeltas, dL_dts, dL_dtotal_samples): rays_a, ts = ctx.saved_tensors segments = torch.cat([rays_a[:, 1], rays_a[-1:, 1]+rays_a[-1:, 2]]) dL_drays_o = segment_csr(dL_dxyzs, segments) dL_drays_d = \ segment_csr(dL_dxyzs*rearrange(ts, 'n -> n 1')+dL_ddirs, segments) return dL_drays_o, dL_drays_d, None, None, None, None, None, None, None더보기Links for more information
// ray marching utils // below code is based on https://github.com/ashawkey/torch-ngp/blob/main/raymarching/src/raymarching.cu __global__ void raymarching_train_kernel( const torch::PackedTensorAccessor32<float, 2, torch::RestrictPtrTraits> rays_o, const torch::PackedTensorAccessor32<float, 2, torch::RestrictPtrTraits> rays_d, const torch::PackedTensorAccessor32<float, 2, torch::RestrictPtrTraits> hits_t, const uint8_t* __restrict__ density_bitfield, const int cascades, const int grid_size, const float scale, const float exp_step_factor, const torch::PackedTensorAccessor32<float, 1, torch::RestrictPtrTraits> noise, const int max_samples, int* __restrict__ counter, torch::PackedTensorAccessor64<int64_t, 2, torch::RestrictPtrTraits> rays_a, torch::PackedTensorAccessor32<float, 2, torch::RestrictPtrTraits> xyzs, torch::PackedTensorAccessor32<float, 2, torch::RestrictPtrTraits> dirs, torch::PackedTensorAccessor32<float, 1, torch::RestrictPtrTraits> deltas, torch::PackedTensorAccessor32<float, 1, torch::RestrictPtrTraits> ts ){ const int r = blockIdx.x * blockDim.x + threadIdx.x; if (r >= rays_o.size(0)) return; const uint32_t grid_size3 = grid_size*grid_size*grid_size; const float grid_size_inv = 1.0f/grid_size; const float ox = rays_o[r][0], oy = rays_o[r][1], oz = rays_o[r][2]; const float dx = rays_d[r][0], dy = rays_d[r][1], dz = rays_d[r][2]; const float dx_inv = 1.0f/dx, dy_inv = 1.0f/dy, dz_inv = 1.0f/dz; float t1 = hits_t[r][0], t2 = hits_t[r][1]; if (t1>=0) { // only perturb the starting t const float dt = calc_dt(t1, exp_step_factor, max_samples, grid_size, scale); t1 += dt*noise[r]; } // first pass: compute the number of samples on the ray float t = t1; int N_samples = 0; // if t1 < 0 (no hit) this loop will be skipped (N_samples will be 0) while (0<=t && t<t2 && N_samples<max_samples){ # caculating ray-box intersection points const float x = ox + (t * dx), y = oy + (t * dy), z = oz + (t * dz); const float dt = calc_dt(t, exp_step_factor, max_samples, grid_size, scale); const int mip = max(mip_from_pos(x, y, z, cascades), mip_from_dt(dt, grid_size, cascades)); const float mip_bound = fminf(scalbnf(1.0f, mip-1), scale); const float mip_bound_inv = 1/mip_bound; // round down to nearest grid position const int nx = clamp(0.5f*(x*mip_bound_inv+1)*grid_size, 0.0f, grid_size-1.0f); const int ny = clamp(0.5f*(y*mip_bound_inv+1)*grid_size, 0.0f, grid_size-1.0f); const int nz = clamp(0.5f*(z*mip_bound_inv+1)*grid_size, 0.0f, grid_size-1.0f); const uint32_t idx = mip*grid_size3 + __morton3D(nx, ny, nz); const bool occ = density_bitfield[idx/8] & (1<<(idx%8)); if (occ) { t += dt; N_samples++; } else { // skip until the next voxel const float tx = (((nx+0.5f+0.5f*signf(dx))*grid_size_inv*2-1)*mip_bound-x)*dx_inv; const float ty = (((ny+0.5f+0.5f*signf(dy))*grid_size_inv*2-1)*mip_bound-y)*dy_inv; const float tz = (((nz+0.5f+0.5f*signf(dz))*grid_size_inv*2-1)*mip_bound-z)*dz_inv; const float t_target = t + fmaxf(0.0f, fminf(tx, fminf(ty, tz))); do { t += calc_dt(t, exp_step_factor, max_samples, grid_size, scale); } while (t < t_target); } } // second pass: write to output const int start_idx = atomicAdd(counter, N_samples); const int ray_count = atomicAdd(counter+1, 1); rays_a[ray_count][0] = r; rays_a[ray_count][1] = start_idx; rays_a[ray_count][2] = N_samples; t = t1; int samples = 0; while (t<t2 && samples<N_samples){ const float x = ox+t*dx, y = oy+t*dy, z = oz+t*dz; const float dt = calc_dt(t, exp_step_factor, max_samples, grid_size, scale); const int mip = max(mip_from_pos(x, y, z, cascades), mip_from_dt(dt, grid_size, cascades)); const float mip_bound = fminf(scalbnf(1.0f, mip-1), scale); const float mip_bound_inv = 1/mip_bound; // round down to nearest grid position const int nx = clamp(0.5f*(x*mip_bound_inv+1)*grid_size, 0.0f, grid_size-1.0f); const int ny = clamp(0.5f*(y*mip_bound_inv+1)*grid_size, 0.0f, grid_size-1.0f); const int nz = clamp(0.5f*(z*mip_bound_inv+1)*grid_size, 0.0f, grid_size-1.0f); const uint32_t idx = mip*grid_size3 + __morton3D(nx, ny, nz); const bool occ = density_bitfield[idx/8] & (1<<(idx%8)); if (occ) { const int s = start_idx + samples; xyzs[s][0] = x; xyzs[s][1] = y; xyzs[s][2] = z; dirs[s][0] = dx; dirs[s][1] = dy; dirs[s][2] = dz; ts[s] = t; deltas[s] = dt; t += dt; samples++; } else { // skip until the next voxel const float tx = (((nx+0.5f+0.5f*signf(dx))*grid_size_inv*2-1)*mip_bound-x)*dx_inv; const float ty = (((ny+0.5f+0.5f*signf(dy))*grid_size_inv*2-1)*mip_bound-y)*dy_inv; const float tz = (((nz+0.5f+0.5f*signf(dz))*grid_size_inv*2-1)*mip_bound-z)*dz_inv; const float t_target = t + fmaxf(0.0f, fminf(tx, fminf(ty, tz))); do { t += calc_dt(t, exp_step_factor, max_samples, grid_size, scale); } while (t < t_target); } } }Calculate $d_{t}$: t * exp_step_factor의 범위를 [SQRT3/max_samples, SQRT3 * 2 * scale / grid_size]로 한정시키기
inline __host__ __device__ float calc_dt(float t, float exp_step_factor, int max_samples, int grid_size, float scale){ return clamp(t*exp_step_factor, SQRT3/max_samples, SQRT3*2*scale/grid_size); }mip from pos:
- Example input range of |xyz| and return value of this function
- [0, 0.5) -> 0
- [0.5, 1) -> 1
- [1, 2) -> 2
inline __device__ int mip_from_pos(const float x, const float y, const float z, const int cascades) { const float mx = fmaxf(fabsf(x), fmaxf(fabs(y), fabs(z))); int exponent; frexpf(mx, &exponent); return min(cascades-1, max(0, exponent+1)); }mip from dt:
- Example input range of dt and return value of this function
- [0, 1/grid_size) -> 0
- [1/grid_size, 2/grid_size) -> 1
- [2/grid_size, 4/grid_size) -> 2
inline __device__ int mip_from_dt(float dt, int grid_size, int cascades) { int exponent; frexpf(dt*grid_size, &exponent); return min(cascades-1, max(0, exponent)); }morton3D: to convert a certain set of integer coordinates to a Morton code, you have to convert the decimal values to binary and interleave the bits of each coordinate.
- (x,y,z) = (5,9,1) = (0101,1001,0001)
- Interleaving the bits results in: 010001000111 = 1095 th cell along the Z-curve.
inline __host__ __device__ uint32_t __morton3D(uint32_t x, uint32_t y, uint32_t z) { uint32_t xx = __expand_bits(x); uint32_t yy = __expand_bits(y); uint32_t zz = __expand_bits(z); return xx | (yy << 1) | (zz << 2); }Volume Renderer (2-2-2)
Ray마다 서로 다른 개수의 샘플들을 가지고 볼륨 렌더링을 진행한다. 이 과정은 학습시에만 사용한다.
- ray_a로부터 제공받은 ray_idx의 sample들을 합치기
front to back compositing (using 'composite_train_fw') - 투과율(T)이 경계값(T_threshold) 이하면 멈추기
class VolumeRenderer(torch.autograd.Function): """ Volume rendering with different number of samples per ray Used in training only Inputs: sigmas: (N) rgbs: (N, 3) deltas: (N) ts: (N) rays_a: (N_rays, 3) ray_idx, start_idx, N_samples meaning each entry corresponds to the @ray_idx th ray, whose samples are [start_idx:start_idx+N_samples] T_threshold: float, stop the ray if the transmittance is below it Outputs: total_samples: int, total effective samples opacity: (N_rays) depth: (N_rays) rgb: (N_rays, 3) ws: (N) sample point weights """ @staticmethod @custom_fwd(cast_inputs=torch.float32) def forward(ctx, sigmas, rgbs, deltas, ts, rays_a, T_threshold): # ray_idx의 samples를 합치기 (front to back compositing) total_samples, opacity, depth, rgb, ws = \ vren.composite_train_fw(sigmas, rgbs, deltas, ts, rays_a, T_threshold) ctx.save_for_backward(sigmas, rgbs, deltas, ts, rays_a, opacity, depth, rgb, ws) ctx.T_threshold = T_threshold return total_samples.sum(), opacity, depth, rgb, ws @staticmethod @custom_bwd def backward(ctx, dL_dtotal_samples, dL_dopacity, dL_ddepth, dL_drgb, dL_dws): sigmas, rgbs, deltas, ts, rays_a, \ opacity, depth, rgb, ws = ctx.saved_tensors dL_dsigmas, dL_drgbs = \ vren.composite_train_bw(dL_dopacity, dL_ddepth, dL_drgb, dL_dws, sigmas, rgbs, ws, deltas, ts, rays_a, opacity, depth, rgb, ctx.T_threshold) return dL_dsigmas, dL_drgbs, None, None, None, None더보기composite train fw:
Outputs
- total_samples
- opacity
- depth
- rgb
- ws
__global__ std::vector<torch::Tensor> composite_train_fw_kernel( const torch::PackedTensorAccessor<scalar_t, 1, torch::RestrictPtrTraits, size_t> sigmas, const torch::PackedTensorAccessor<scalar_t, 2, torch::RestrictPtrTraits, size_t> rgbs, const torch::PackedTensorAccessor<scalar_t, 1, torch::RestrictPtrTraits, size_t> deltas, const torch::PackedTensorAccessor<scalar_t, 1, torch::RestrictPtrTraits, size_t> ts, const torch::PackedTensorAccessor64<int64_t, 2, torch::RestrictPtrTraits> rays_a, const scalar_t T_threshold, torch::PackedTensorAccessor64<int64_t, 1, torch::RestrictPtrTraits> total_samples, torch::PackedTensorAccessor<scalar_t, 1, torch::RestrictPtrTraits, size_t> opacity, torch::PackedTensorAccessor<scalar_t, 1, torch::RestrictPtrTraits, size_t> depth, torch::PackedTensorAccessor<scalar_t, 2, torch::RestrictPtrTraits, size_t> rgb, torch::PackedTensorAccessor<scalar_t, 1, torch::RestrictPtrTraits, size_t> ws ){ const int n = blockIdx.x * blockDim.x + threadIdx.x; if (n >= opacity.size(0)) return; const int ray_idx = rays_a[n][0], start_idx = rays_a[n][1], N_samples = rays_a[n][2]; // front to back compositing int samples = 0; scalar_t T = 1.0f; while (samples < N_samples) { const int s = start_idx + samples; const scalar_t a = 1.0f - __expf(-sigmas[s]*deltas[s]); const scalar_t w = a * T; // weight of the sample point rgb[ray_idx][0] += w*rgbs[s][0]; rgb[ray_idx][1] += w*rgbs[s][1]; rgb[ray_idx][2] += w*rgbs[s][2]; depth[ray_idx] += w*ts[s]; opacity[ray_idx] += w; ws[s] = w; T *= 1.0f-a; if (T <= T_threshold) break; // ray has enough opacity samples++; } total_samples[ray_idx] = samples; return {total_samples, opacity, depth, rgb, ws}; }Unproject
def back_project(coords, origin, voxel_size, feats, KRcam): ''' Unproject the image fetures to form a 3D (sparse) feature volume Inputs: coords: coordinates of voxels, # (num of voxels, 4) (4 : batch ind, x, y, z) origin: origin of the partial voxel volume (xyz position of voxel (0, 0, 0)) # (batch size, 3) (3: x, y, z) voxel_size: floats specifying the size of a voxel feats: image features # (num of views, batch size, C, H, W) KRcam: projection matrix # (num of views, batch size, 4, 4) Outputs: feature_volume_all: 3D feature volumes # (num of voxels, c + 1) count: number of times each voxel can be seen # (num of voxels,) ''' n_views, bs, c, h, w = feats.shape feature_volume_all = torch.zeros(coords.shape[0], c + 1).cuda() count = torch.zeros(coords.shape[0]).cuda() for batch in range(bs): batch_ind = torch.nonzero(coords[:, 0] == batch).squeeze(1) coords_batch = coords[batch_ind][:, 1:] coords_batch = coords_batch.view(-1, 3) origin_batch = origin[batch].unsqueeze(0) feats_batch = feats[:, batch] proj_batch = KRcam[:, batch] grid_batch = coords_batch * voxel_size + origin_batch.float() rs_grid = grid_batch.unsqueeze(0).expand(n_views, -1, -1) rs_grid = rs_grid.permute(0, 2, 1).contiguous() nV = rs_grid.shape[-1] rs_grid = torch.cat([rs_grid, torch.ones([n_views, 1, nV]).cuda()], dim=1) # Project grid im_p = proj_batch @ rs_grid im_x, im_y, im_z = im_p[:, 0], im_p[:, 1], im_p[:, 2] im_x = im_x / im_z im_y = im_y / im_z im_grid = torch.stack([2 * im_x / (w - 1) - 1, 2 * im_y / (h - 1) - 1], dim=-1) mask = im_grid.abs() <= 1 mask = (mask.sum(dim=-1) == 2) & (im_z > 0) feats_batch = feats_batch.view(n_views, c, h, w) im_grid = im_grid.view(n_views, 1, -1, 2) features = grid_sample(feats_batch, im_grid, padding_mode='zeros', align_corners=True) features = features.view(n_views, c, -1) mask = mask.view(n_views, -1) im_z = im_z.view(n_views, -1) # remove nan features[mask.unsqueeze(1).expand(-1, c, -1) == False] = 0 im_z[mask == False] = 0 count[batch_ind] = mask.sum(dim=0).float() # aggregate multi view features = features.sum(dim=0) mask = mask.sum(dim=0) invalid_mask = mask == 0 mask[invalid_mask] = 1 in_scope_mask = mask.unsqueeze(0) features /= in_scope_mask features = features.permute(1, 0).contiguous() # concat normalized depth value im_z = im_z.sum(dim=0).unsqueeze(1) / in_scope_mask.permute(1, 0).contiguous() im_z_mean = im_z[im_z > 0].mean() im_z_std = torch.norm(im_z[im_z > 0] - im_z_mean) + 1e-5 im_z_norm = (im_z - im_z_mean) / im_z_std im_z_norm[im_z <= 0] = 0 features = torch.cat([features, im_z_norm], dim=1) feature_volume_all[batch_ind] = features return feature_volume_all, countTrain (1)
class NeRFSystem(LightningModule): def __init__(self, hparams): super().__init__() self.save_hyperparameters(hparams) self.warmup_steps = 256 self.update_interval = 16 self.loss = NeRFLoss(lambda_distortion=self.hparams.distortion_loss_w) self.train_psnr = PeakSignalNoiseRatio(data_range=1) self.val_psnr = PeakSignalNoiseRatio(data_range=1) self.val_ssim = StructuralSimilarityIndexMeasure(data_range=1) if self.hparams.eval_lpips: self.val_lpips = LearnedPerceptualImagePatchSimilarity('vgg') for p in self.val_lpips.net.parameters(): p.requires_grad = False self.model = NeRFusion2(scale=self.hparams.scale) def forward(self, batch, split): if split=='train': poses = self.poses[batch['img_idxs']] directions = self.directions[batch['pix_idxs']] else: poses = batch['pose'] directions = self.directions if self.hparams.optimize_ext: dR = axisangle_to_R(self.dR[batch['img_idxs']]) poses[..., :3] = dR @ poses[..., :3] poses[..., 3] += self.dT[batch['img_idxs']] rays_o, rays_d = get_rays(directions, poses) kwargs = {'test_time': split!='train', 'random_bg': self.hparams.random_bg} if self.hparams.scale > 0.5: kwargs['exp_step_factor'] = 1/256 return render(self.model, rays_o, rays_d, **kwargs) def on_train_start(self): self.model.prune_cells(self.train_dataset.K.to(self.device), self.poses, self.train_dataset.img_wh) def training_step(self, batch, batch_nb, *args): if self.global_step%self.update_interval == 0: self.model.update_density_grid(0.01*MAX_SAMPLES/3**0.5, warmup=self.global_step<self.warmup_steps, erode=self.hparams.dataset_name=='colmap') results = self(batch, split='train') loss_d = self.loss(results, batch) loss = sum(lo.mean() for lo in loss_d.values()) with torch.no_grad(): self.train_psnr(results['rgb'], batch['rgb']) self.log('lr', self.net_opt.param_groups[0]['lr']) self.log('train/loss', loss) # ray marching samples per ray (occupied space on the ray) self.log('train/rm_s', results['rm_samples']/len(batch['rgb']), True) # volume rendering samples per ray (stops marching when transmittance drops below 1e-4) self.log('train/vr_s', results['vr_samples']/len(batch['rgb']), True) self.log('train/psnr', self.train_psnr, True) return loss더보기전체 Training 코드
class NeRFSystem(LightningModule): def __init__(self, hparams): super().__init__() self.save_hyperparameters(hparams) self.warmup_steps = 256 self.update_interval = 16 self.loss = NeRFLoss(lambda_distortion=self.hparams.distortion_loss_w) self.train_psnr = PeakSignalNoiseRatio(data_range=1) self.val_psnr = PeakSignalNoiseRatio(data_range=1) self.val_ssim = StructuralSimilarityIndexMeasure(data_range=1) if self.hparams.eval_lpips: self.val_lpips = LearnedPerceptualImagePatchSimilarity('vgg') for p in self.val_lpips.net.parameters(): p.requires_grad = False self.model = NeRFusion2(scale=self.hparams.scale) # scale=0.5 def forward(self, batch, split): if split=='train': poses = self.poses[batch['img_idxs']] directions = self.directions[batch['pix_idxs']] else: poses = batch['pose'] directions = self.directions if self.hparams.optimize_ext: dR = axisangle_to_R(self.dR[batch['img_idxs']]) poses[..., :3] = dR @ poses[..., :3] poses[..., 3] += self.dT[batch['img_idxs']] rays_o, rays_d = get_rays(directions, poses) kwargs = {'test_time': split!='train', 'random_bg': self.hparams.random_bg} if self.hparams.scale > 0.5: kwargs['exp_step_factor'] = 1/256 return render(self.model, rays_o, rays_d, **kwargs) def setup(self, stage): dataset = dataset_dict[self.hparams.dataset_name] kwargs = {'root_dir': self.hparams.root_dir, 'downsample': self.hparams.downsample} self.train_dataset = dataset(split=self.hparams.split, **kwargs) self.train_dataset.batch_size = self.hparams.batch_size self.train_dataset.ray_sampling_strategy = self.hparams.ray_sampling_strategy self.test_dataset = dataset(split='test', **kwargs) # define additional parameters self.register_buffer('directions', self.train_dataset.directions.to(self.device)) self.register_buffer('poses', self.train_dataset.poses.to(self.device)) if self.hparams.optimize_ext: N = len(self.train_dataset.poses) self.register_parameter('dR', nn.Parameter(torch.zeros(N, 3, device=self.device))) self.register_parameter('dT', nn.Parameter(torch.zeros(N, 3, device=self.device))) def configure_optimizers(self): load_ckpt(self.model, self.hparams.weight_path) net_params = [] for n, p in self.named_parameters(): if n not in ['dR', 'dT']: net_params += [p] opts = [] self.net_opt = FusedAdam(net_params, self.hparams.lr, eps=1e-15) opts += [self.net_opt] if self.hparams.optimize_ext: opts += [FusedAdam([self.dR, self.dT], 1e-6)] # learning rate is hard-coded net_sch = CosineAnnealingLR(self.net_opt, self.hparams.num_epochs, self.hparams.lr/30) return opts, [net_sch] def train_dataloader(self): return DataLoader(self.train_dataset, num_workers=16, persistent_workers=True, batch_size=None, pin_memory=True) def val_dataloader(self): return DataLoader(self.test_dataset, num_workers=8, batch_size=None, pin_memory=True) def on_train_start(self): self.model.prune_cells(self.train_dataset.K.to(self.device), self.poses, self.train_dataset.img_wh) def training_step(self, batch, batch_nb, *args): if self.global_step%self.update_interval == 0: self.model.update_density_grid(0.01*MAX_SAMPLES/3**0.5, warmup=self.global_step<self.warmup_steps, erode=self.hparams.dataset_name=='colmap') results = self(batch, split='train') loss_d = self.loss(results, batch) loss = sum(lo.mean() for lo in loss_d.values()) with torch.no_grad(): self.train_psnr(results['rgb'], batch['rgb']) self.log('lr', self.net_opt.param_groups[0]['lr']) self.log('train/loss', loss) # ray marching samples per ray (occupied space on the ray) self.log('train/rm_s', results['rm_samples']/len(batch['rgb']), True) # volume rendering samples per ray (stops marching when transmittance drops below 1e-4) self.log('train/vr_s', results['vr_samples']/len(batch['rgb']), True) self.log('train/psnr', self.train_psnr, True) return loss def on_validation_start(self): torch.cuda.empty_cache() if not self.hparams.no_save_test: self.val_dir = f'results/{self.hparams.dataset_name}/{self.hparams.exp_name}' os.makedirs(self.val_dir, exist_ok=True) def validation_step(self, batch, batch_nb): rgb_gt = batch['rgb'] results = self(batch, split='test') logs = {} # compute each metric per image self.val_psnr(results['rgb'], rgb_gt) logs['psnr'] = self.val_psnr.compute() self.val_psnr.reset() w, h = self.train_dataset.img_wh rgb_pred = rearrange(results['rgb'], '(h w) c -> 1 c h w', h=h) rgb_gt = rearrange(rgb_gt, '(h w) c -> 1 c h w', h=h) self.val_ssim(rgb_pred, rgb_gt) logs['ssim'] = self.val_ssim.compute() self.val_ssim.reset() if self.hparams.eval_lpips: self.val_lpips(torch.clip(rgb_pred*2-1, -1, 1), torch.clip(rgb_gt*2-1, -1, 1)) logs['lpips'] = self.val_lpips.compute() self.val_lpips.reset() if not self.hparams.no_save_test: # save test image to disk idx = batch['img_idxs'] rgb_pred = rearrange(results['rgb'].cpu().numpy(), '(h w) c -> h w c', h=h) rgb_pred = (rgb_pred*255).astype(np.uint8) imageio.imsave(os.path.join(self.val_dir, f'{idx:03d}.png'), rgb_pred) return logs def validation_epoch_end(self, outputs): psnrs = torch.stack([x['psnr'] for x in outputs]) mean_psnr = all_gather_ddp_if_available(psnrs).mean() self.log('test/psnr', mean_psnr, True) ssims = torch.stack([x['ssim'] for x in outputs]) mean_ssim = all_gather_ddp_if_available(ssims).mean() self.log('test/ssim', mean_ssim) if self.hparams.eval_lpips: lpipss = torch.stack([x['lpips'] for x in outputs]) mean_lpips = all_gather_ddp_if_available(lpipss).mean() self.log('test/lpips_vgg', mean_lpips) def get_progress_bar_dict(self): # don't show the version number items = super().get_progress_bar_dict() items.pop("v_num", None) return items