-
[ 작성중 ]
ICCV 2019
UCL, Caltech, Niantic
Yoonwoo Jeong, Seungjoo Shin, Junha Lee, Chris Choy, Anima Anandkumar, Minsu Cho, Jaesik Park
pdf codeSummary
- Self-supervised 방식으로 단안 렌즈 카메라의 Depth를 추정.
- 단일 프레임에서 depth를 예측하기 위해 depth 및 pose를 예측하는 두 가지 네트워크의 조합을 사용. 다양한 손실 함수와 연속적인 프레임을 사용하여 이 두 가지의 네트워크를 훈련시킨다.
- Pose 추정 네트워크는 학습을 제한하기 위해 사용한다. (Constrained Learning)
- 정답(Ground Truth, GT) 데이터셋 없이 연속적인 프레임 (t-1, t, t+1)을 사용하여 학습한다.
Contributions
- Depth map을 이용한 손실함수 제안 (An appearance matching loss) → Monocular supervision 사용시 발생할 수 있는 pixel occlusion을 보완해준다.
- 중요하지 않은 픽셀의 계산을 제거하는 Auto-masking 적용
- Multi-scale depth estimation (A multi-scale appearnace matching loss) → depth artifacts 완화.
Existing Problems
- 기존 Depth estimation시에 단일 이미지로는 삼각측량(triangulation)이 불가능하여 위치가 잘못 추정된다.
Preliminaries
- Disparity (이격): Stereo 정합을 위해 사용하는 눈 또는 렌즈의 좌측(시야) 이미지, 우측(시야) 이미지에서 객체의 위치 차이를 의미한다. Disparity map을 생성하여 깊이 정보를 계산하는 데 사용된다. (두 개의 관찰 지점 사이의 거리 차이)
- Parallax (시차): Disparity와는 달리 카메라의 렌즈 또는 관찰자의 시각적 관점 변화를 포함하는 개념으로, 관찰자 또는 카메라의 시점 변화에 따라 물체가 상대적으로 이동하는 것을 의미한다.
Introduction
- Monocular video vs. Stereo-based supervision
- Using a monocular video data needs to estimate the ego-motion between temporal image pairs during training → Pose estimation network.
- Using stereo data for training makes the camera-pose estimation a one-time offline calibration, but can cause issues related to occlusion and texture-copy artifacts
- Pose Estimation Network
- Input: A finite sequence of frames
- Output: The corresponding camera transformations.
Related Works
Supervised Depth Estimation
단일 이미지에서 추정한 depth는 ill-posed 문제를 내재하고 있다. 하나의 이미지가 다양한 depth에 사영될 수 있기 때문이다.
이미지의 색깔과 그에 상응하는 depth 를 찾는 방식을 사용한 기존의 접근법
- Combining local predictions
- Non-parametric scene sampling
- End-to-end supervised learning
적용성을 높이기 위해 Weakly supervised training data를 사용한 방법 → (아래의 방법들은) depth 정보 또는 annotation 등이 추가적으로 필요하다.
- Known object sizes
- Sparse ordinal depths
- Supervised-appearance matching terms
- Unpaired synthetic depth data
Conventional Structure from Motion (SfM) Pipelines
Generate sparse training signal for both camera pose and depth, where SfM is typically run as a pre-processing step decoupled from learning.
Self-Supervised Depth Estimation
GT 데이터가 없는 상황에서 복원된 이미지를 supervison의 메타로 사용하는 방법이 있다.
Self-supervised Stereo Training
네트워크 훈련시에 Synchronized stereo pairs를 사용하고, 해당 쌍을 통해 pixel disparities를 추정한다. 테스트시에는 monocular 깊이 추정이 가능하다. 다음은 stereo training을 사용한 예시이다.
- Discretized depth 를 사용하여 novel view 를 처리 (범위의 형태로 기존에 학습한 depth에 novel view를 편입시킴)
- Continuous disparity values 를 사용하여 위를 확장시킨 방법
- including a left-right depth consistency term 을 적용하여 현재의 supervised methods를 한 단계 발전시킨 방법
- GAN 등을 사용하여 stereo 기반 방법을 보강한 것
Self-supervised Monocular Training
Monocular video 이용시 Stereo training 에 비해 제약이 덜하다. 연속된 프레임을 이용하여 훈련하며, depth와 프레임간의 카메라 pose 를 추정해야 한다.
- Object motion을 추정하기 위해 motion을 rigid와 non-rigid로 나누어 depth와 optical flow를 예측한다. 이 때, depth와 flow를 jointly 하게 훈련시키는 경우엔 성능개선이 되지 않는 것을 확인하였다.
- Stereo based training 에 비해 성능이 좋지 않지만, 점점 차이가 줄어들고 있다.
Appearance Based Losses
훈련은 프레임 간 물체 표면(예: 밝기 불변성, brightness constancy) 및 재료 특성(e.g. Lambertian)에 영향을 많이 받는다. 지역적 구조를 기반으로 계산한 Appearance Loss를 포함하면 depth 추정 성능이 큰 폭으로 개선된다.
Methods
- Input: A single color ($I_{t}$)
- Output: A depth map ($D_{t}$)
1. Self-Supervised Training
두가지 이미지의 상대적인 pose를 바탕으로 하나의 이미지의 각 픽셀을 복원할 수 있는 틀린 depth 정보가 수많이 존재한다.
Classical binocular, Multi-view stereo: 이러한 모호성을 depth map에 smoothness를 부여하고 patch별로 photo-consistency로 per-pixel depth를 계산하여 해결하였다.
Photometric reprojection error 를 최소화 하는 방식으로 문제를 정의하였다. 훈련시에는 Camera pose 와 depth를 동시에 최적화시킨다.
- Target image, $I_{t}$
- Pose of target image, $T_{t→t^{'}}$
- Source view, $I_{t^{'}} \in \left{ I_{t-1}, I_{t+1} \right}$
- Relative pose for each source view
- Dense depth map, $D_{t}$
- Photometric reprojection error, $L_{p}, pe$
$$L_{p} = \sum_{t^{'}} pe \left( I_{t}, I_{t^{'}→t} \right)$$
$$I_{t^{'}→t} = I_{t^{'}}\left< proj \left( D_{t}, T_{t→t^{'}}, K \right) \right>$$
2. Improved Self-Supervised Depth Estimation

기존의 Monocular method의 depth map이 저품질인 점을 개선하기 위해 추가 네트워크를 구성하지 않으면서 모델을 개선시켰다.
Per-Pixel Minimum Reprojection Loss (Fig. 3(c))
픽셀에 대해 올바른 depth를 추정했더라도 오류로 판정하는 경우가 발생한다. 이는 (ㄱ) 이미지 경계에서 발생한 egomotion으로 인한 시야밖 픽셀 (out-of-view pixels due to egomotion at image boundaries), (ㄴ) 가려진 픽셀 (occluded pixel) 의 두가지 경우가 있다. (ㄱ)을 해결하기 위해 out-of-view pixel을 masking 처리를 하더라도, (ㄴ)에 대해 평균값을 취하면서 발생하는 blurred depth discontinuities 를 해결하지 못한다. 따라서, photometric error를 해결하기 위해 평균을 취하는 방식이 아닌, 최소값을 사용하여 아래와 같은 Loss를 정의한다.
$$L_{p} = \min_{t^'} pe \left( I_{t}, I_{t^{'} → t} \right)$$

Using our minimum reprojection loss significantly reduces artifacts at image borders, improves the sharpness of occlusion bound- aries, and leads to better accuracy. 
Auto-Masking Stationary Pixels

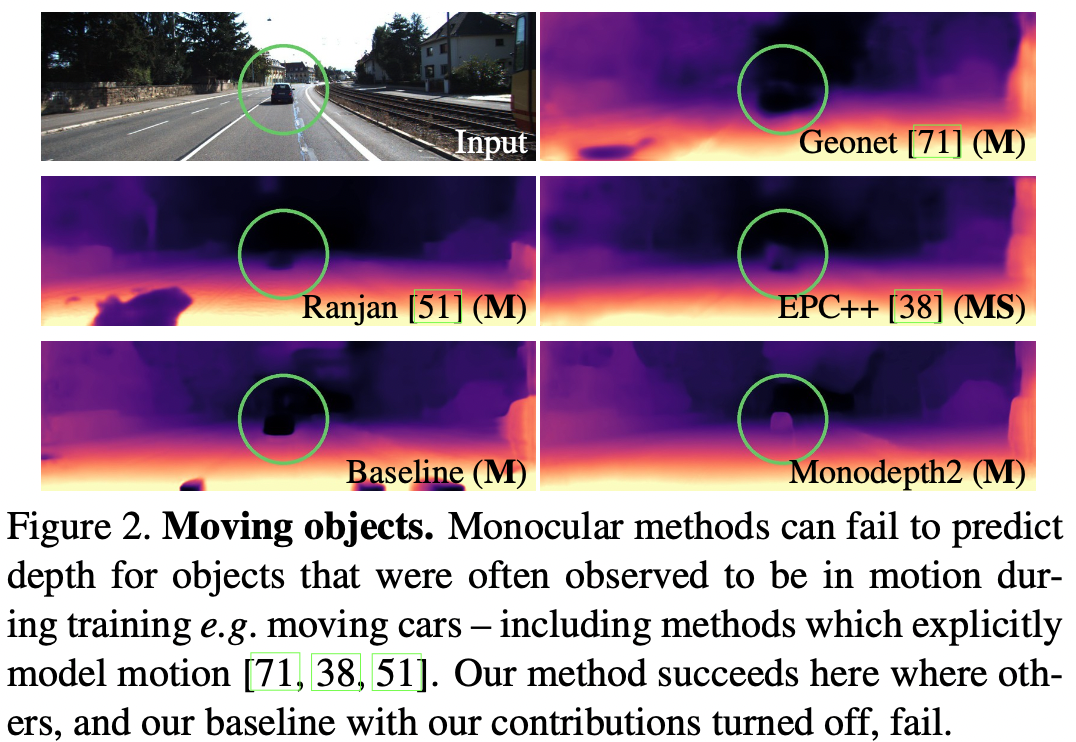
Monocular 기반 학습은 카메라가 움직이고, 장면은 움직이지 않는다는 것을 전제로 한다. 이러한 전제와 다른 경우 depth 추정이 어려워진다 (Fig. 2). 이 논문에서는 per-pixel 마스크(μ)를 사용하여 loss에 적용하고, pixel에 선택적으로 가중치를 적용한다. 이 논문에서는 이전 논문과는 다르게 마스크를 학습하지 않고, 계산된 바이너리 마스크를 적용한다는 차이점이 존재한다. 뒤틀린 이미지(warped image, $I_{t^{'} → t}$)의 reprojection error가 원본 이미지($I_{t^{'}}$)보다 작을 때 바이너리 마스크에 픽셀을 포함시킨다.
$$\mu = \left[ \min_{t^{'}} pe\left( I_{t}, I_{t^{'} → t} \right) < \min_{t^{'}} pe \left( I_{t}, I_{t^{'}} \right) \right]$$
* [] 는 아이버슨 괄호(Inverson Bracket, 참일 때 1 거짓일 때 0 반환)를 의미한다.
Fig. 5에서 확인할 수 있듯, 카메라와 물체가 비슷한 속도로 동시에 이동할 때, 이동하지 않는 물체를 마스킹한다. 또한, 카메라가 이동하지 않는다면 마스크에 이미지의 거의 모든 픽셀이 포함되지 않는다.

(위) 카메라와 물체가 비슷한 속도로 움직일 때, (아래) 카메라가 움직이지 않을 때 3. Additional Considerations
Depth Estimation Network
- Encoder: pre-trained된 ResNet18 모델
- Decoder: 시그모이드 출력을 depth로 변환하는 작업
Pose Estimation Network
ResNet18 네트워크를 통해 6-자유도의 relative pose, Rotation, Translation 을 예측하여 두 프레임 사이의 카메라 관계를 추론한다. 두 개의 color image (t-1, t 번째 프레임)를 입력값으로 받아 t번째 이미지를 예측한다.
Experiments
Conclusion
References